Will your PR ever be Merged?
Staff Engineer at Instruqt
Some of the results (e.g. Vuejs) are skewed by spam. I am currently refining my methodology - if you are curious have a look at merge-chance GitHub issues
Have you ever made an open source contribution? Whether your PR is rejected/ignored or successfully merged can depend on factors other than just the quality of your work. Some projects are just much more responsive, some are very picky about what is accepted and reject anything that does not match their vision.
I extracted Pull Request stats for 40 popular open source GitHub projects to see how likely it is for a PR to ever be merged. In this post you will find contributions to which projects are the best use of your time. Spoiler: some big mature projects do better in this ranking than you would think!
How I chose the projects to analyse
I went with Python, Julia, R and JavaScript, each having 10 repos in the ranking. The aim was to collect a somewhat representative sample of big popular projects among these 4 languages, hence you will see here mostly big names such as React, TensorFlow and Shiny. I am personally interested in broadly understood Data Science so my ranking skews more to this side, since these are the projects I would be more likely to contribute myself. However an open source ranking would not be complete without popular web frameworks in Python (Django, Flask, FastAPI) and some of the most popular js frontend tech (React, Vue), since web development projects are the most active ones on GitHub.
What did I look at?
To answer the question: how likely is it that an average PR gets merged into given repo I looked at proportion of Merged vs closed without merge PRs. I also collected data about stale PRs (open for longer than 90 days) and currently active ones (open but not older than 90 days).
How did I gather the data?
This is an interesting one! At first I used GitHub's REST API and while it was good enough for extracting data from smaller repositories I quickly hit rate-limiting (5k requests per hour) and also got bored of waiting. Fortunately GitHub offers also a GraphQL API which for this specific purpose is orders of magnitude more efficient!
Why is that? For my analysis I need just a few fields from all PRs in a given repo. I used PyGithub lib to fetch the data, fetching PRs seems to incur one HTPP request per paginated result (max 25 entries) which is what I expected but then for fetching the merged status field it had to perform one more HTTP request per PR. As you can imagine that slowed down the execution to a crawl so I had to find another solution, GraphQL performed just one HTTP request per 100 entires and dropped execution time from above an hour for a big repo like react to just around a minute. Have a look at my extraction scripts (both GraphQL and REST) on my GitHub.
Results
OK enough about the data collection. You are probably just curious which projects are most likely to ghost you and your hard work. Let get down to it.
JavaScript Projects Are Selective
First have a look at the list of JS projects I analysed:
- vuejs/vue
- facebook/react
- twbs/bootstrap
- axios/axios
- nodejs/node
- mrdoob/three.js
- mui-org/material-ui
- webpack/webpack
- chartjs/Chart.js
- expressjs/express
For each of them I report the number of successful (merged) PRs, rejected (closed but not merged), stale (open for longer than 90 days) and active (open and less than 90 days old).
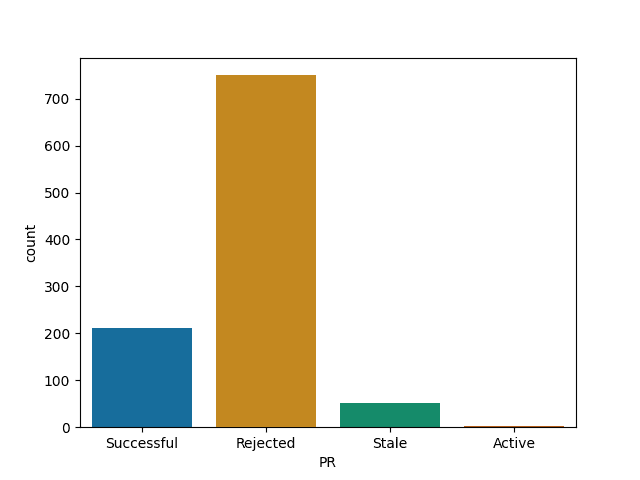
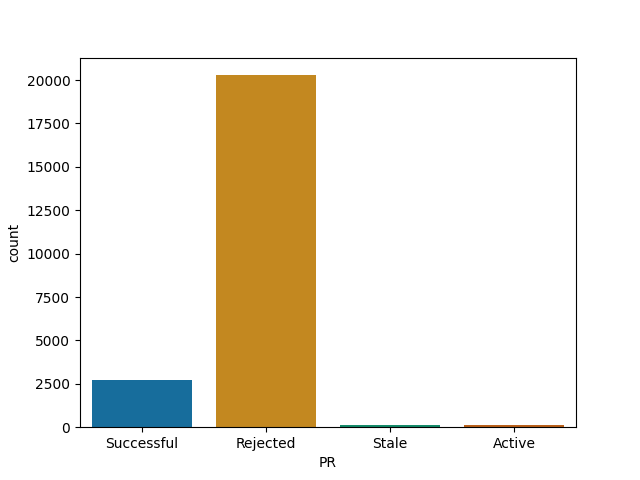
Express and Node are most likely to reject a PR
Express
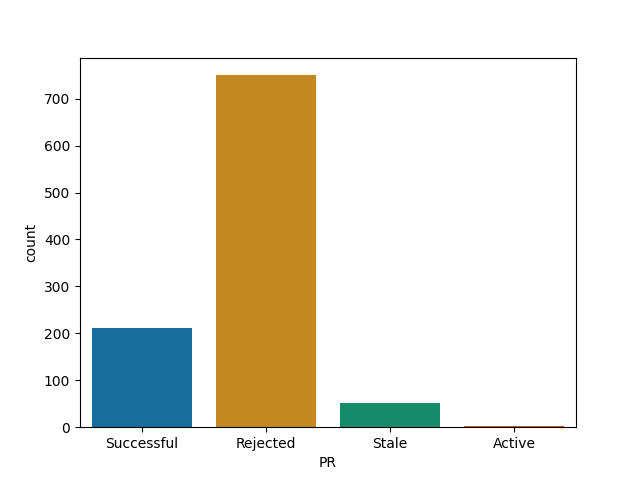 Node
Node
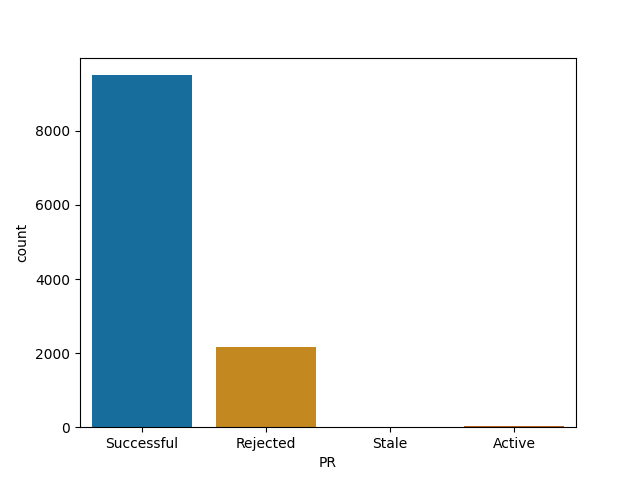
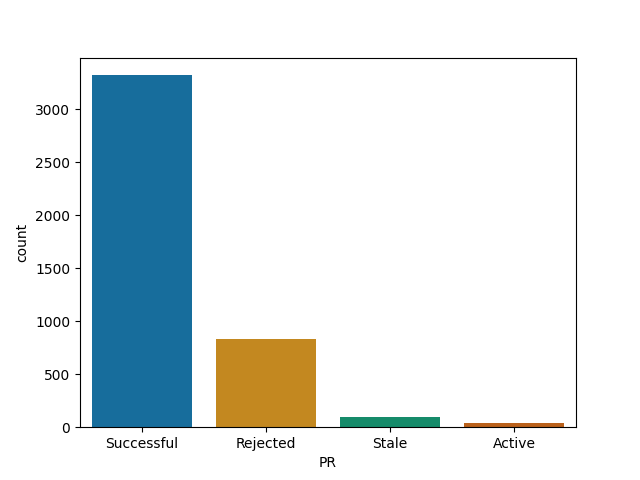
Material-ui and webpack are most likely to merge your PR among big JS projects
Material-ui
Webpack
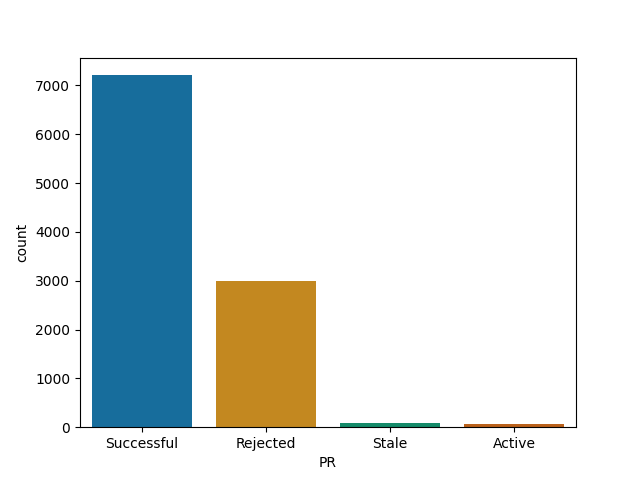
React, while quite selective is more likely to merge than I thought such a big project would be
React
Python Projects Merge PRs more often than JS
Lets have a look at the list of Python projects I analysed:
- tensorflow/tensorflow
- django/django
- pallets/flask
- keras-team/keras
- scikit-learn/scikit-learn
- ageitgey/face_recognition
- 3b1b/manim
- pandas-dev/pandas
- tiangolo/fastapi
- donnemartin/data-science-ipython-notebooks
For each of them I report the number of successful (merged) PRs, rejected (closed but not merged), stale (open for longer than 90 days) and active (open and less than 90 days old).
Big old web projects like Django and Flask are significantly more selective, the chance for merging is still higher than in JS equivalents
Django
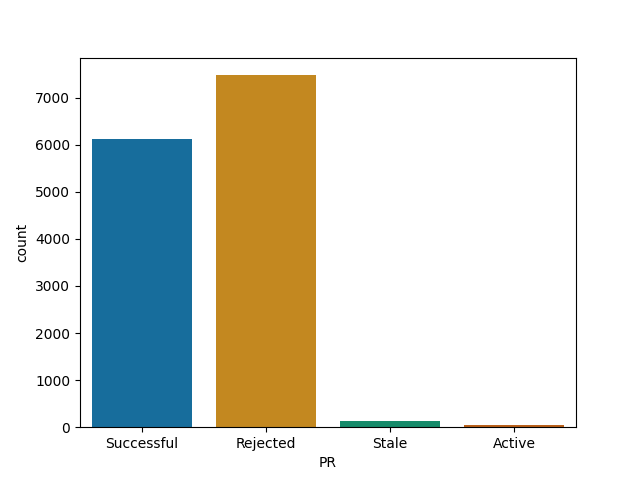
Flask
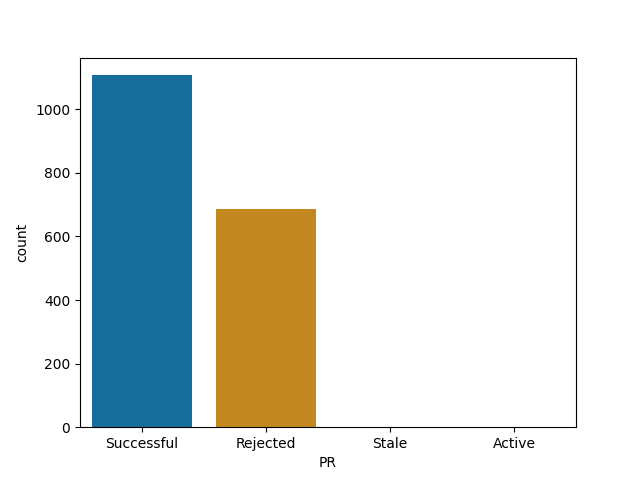
Data related projects merge most of their PRs
Pandas
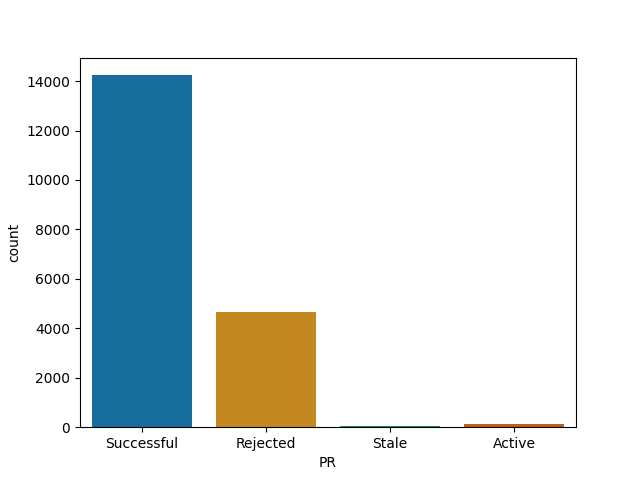
Scikit-learn
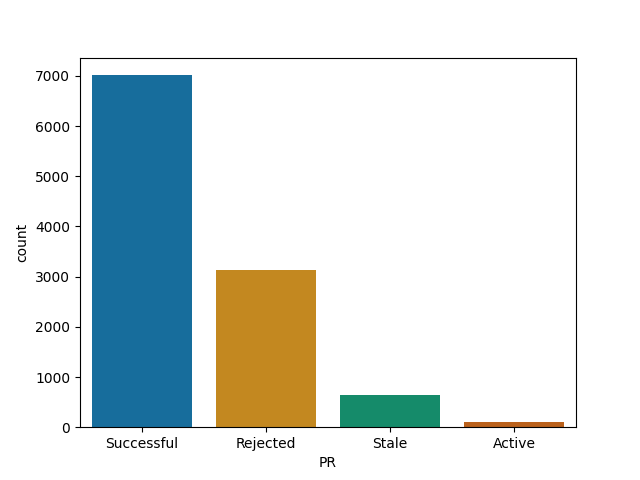
DS Notebooks
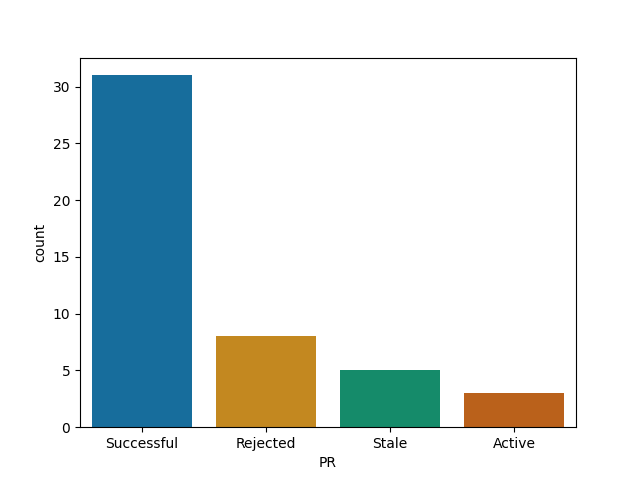
Tensorflow is more welcoming to contributions than I assumed ..
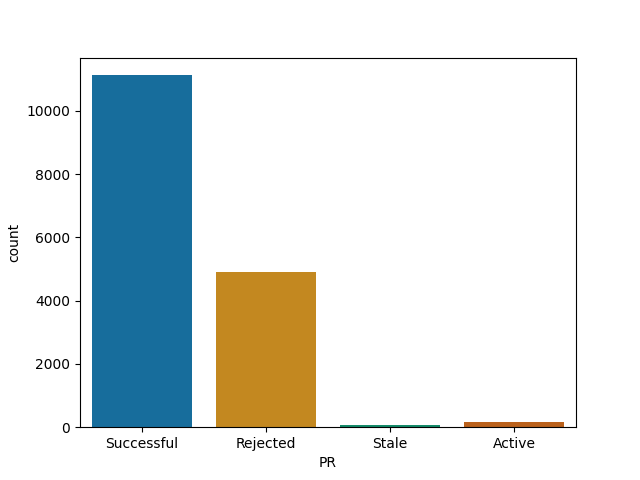
3blue1brown and his popular manim visualisation lib stand out
Manim was open sourced by popular math Youtuber 3blue1brown not so long ago. It seems that there aren't enough maintainers to process deluge of PRs coming from the community. Some help here maybe?
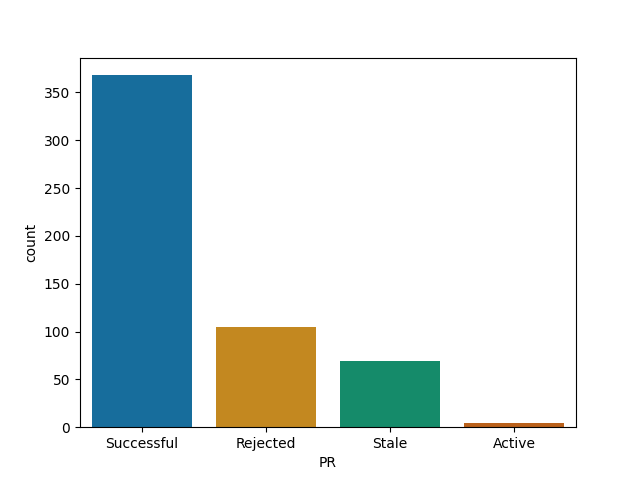
Julia's projects are under active development and welcome contributions
Lets have a look at the list of Julia projects I analysed:
- JuliaAcademy/JuliaTutorials
- JuliaLang/IJulia.jl
- GiovineItalia/Gadfly.jl
- fonsp/Pluto.jl
- SciML/DifferentialEquations.jl
- jump-dev/JuMP.jl
- JuliaPlots/Plots.jl
- JuliaPy/PyCall.jl
- JuliaData/DataFrames.jl
- JuliaLang/julia
For each of them I report the number of successful (merged) PRs, rejected (closed but not merged), stale (open for longer than 90 days) and active (open and less than 90 days old).
Roughly all Julia's repos follow similar pattern - your time is probably well spent here!
JuMP
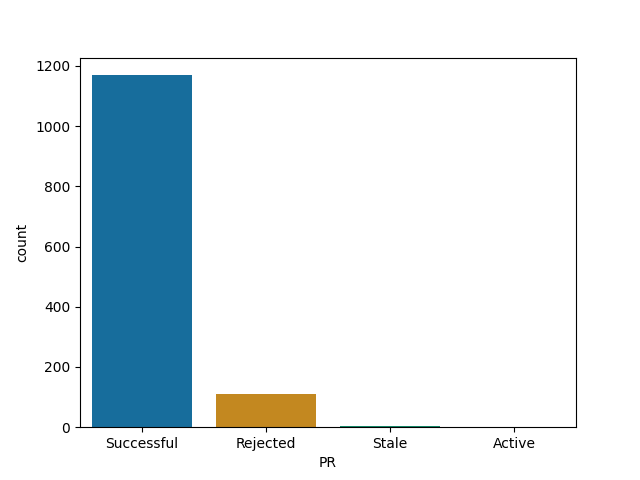
Pluto
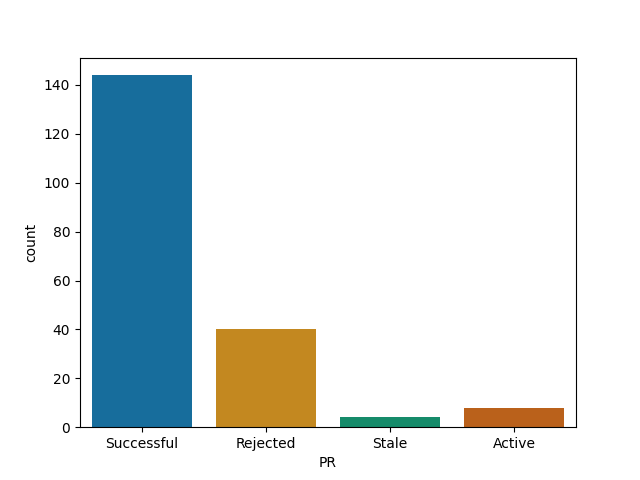
DifferentialEquations
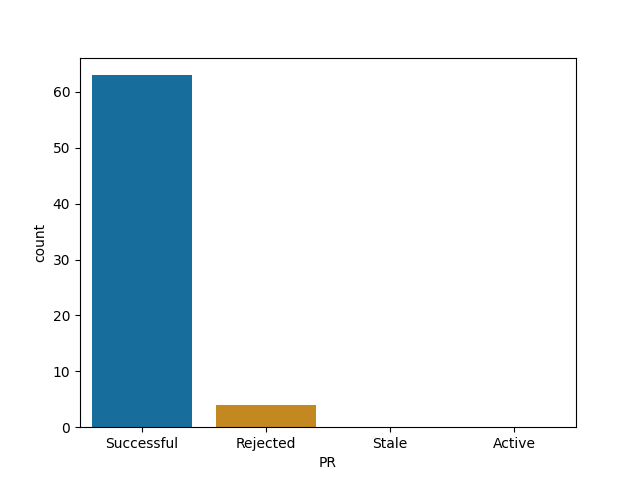
PyCall
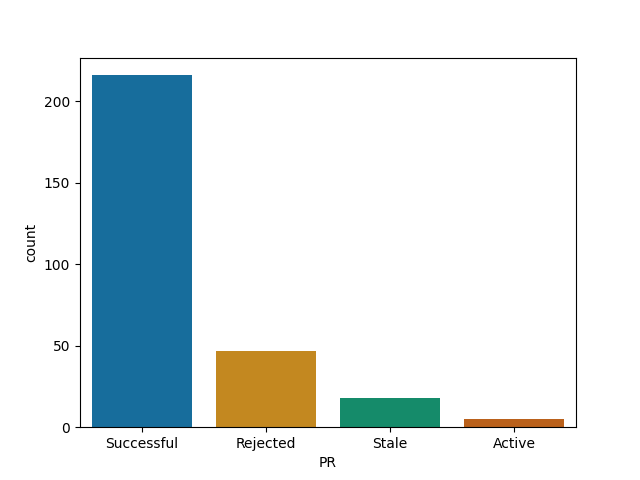
Plots.jl
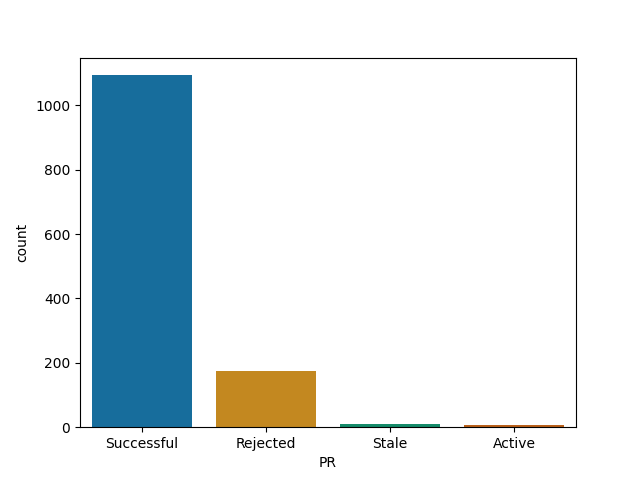
JuliaLang
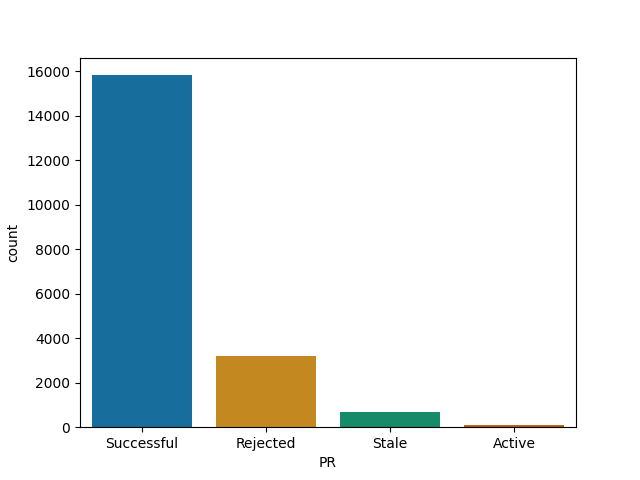
IJulia
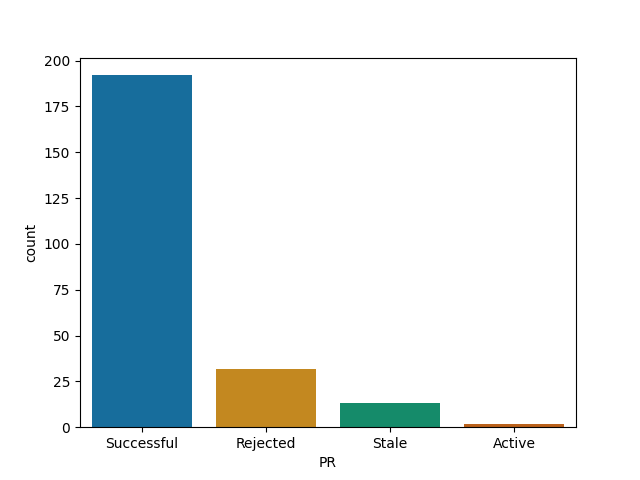
DataFrames
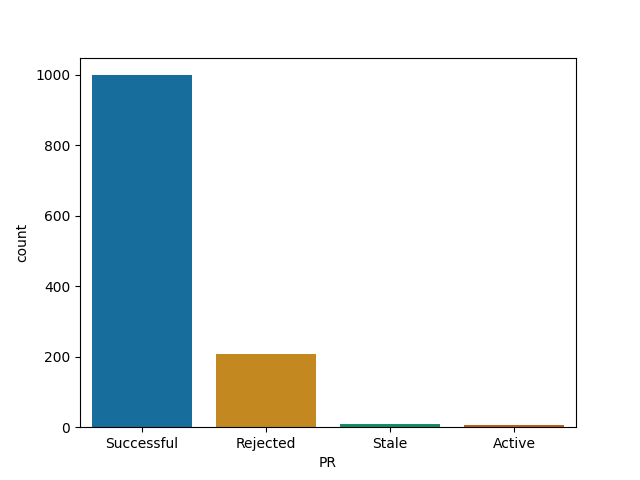
JuliaTutorials
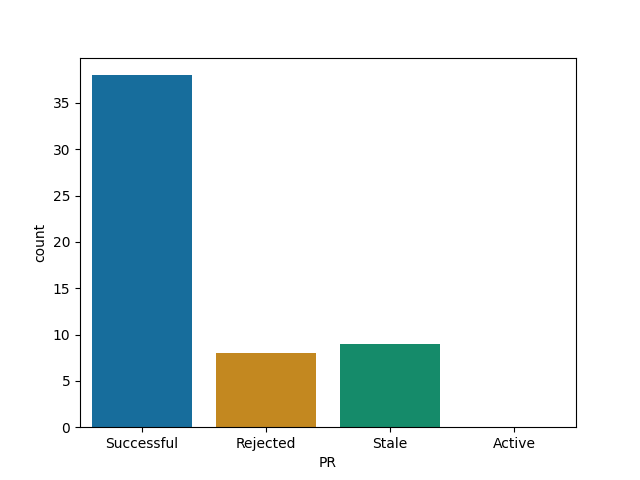
Gadfly
R Also Has some of the most hospitable repos
R projects I analysed:
- tidyverse/ggplot2
- rstudio/shiny
- tidyverse/dplyr
- hadley/r4ds
- r-lib/devtools
- rstudio/rmarkdown
- yihui/knitr
- ropensci/plotly
- mlr-org/mlr
- rich-iannone/DiagrammeR
For each of them I report the number of successful (merged) PRs, rejected (closed but not merged), stale (open for longer than 90 days) and active (open and less than 90 days old).
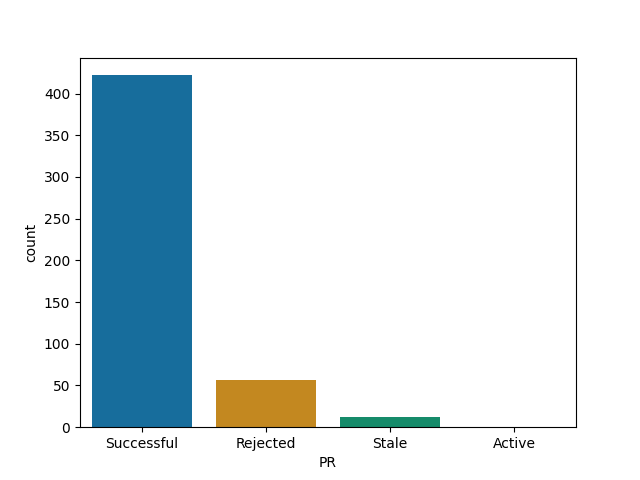
Knitr
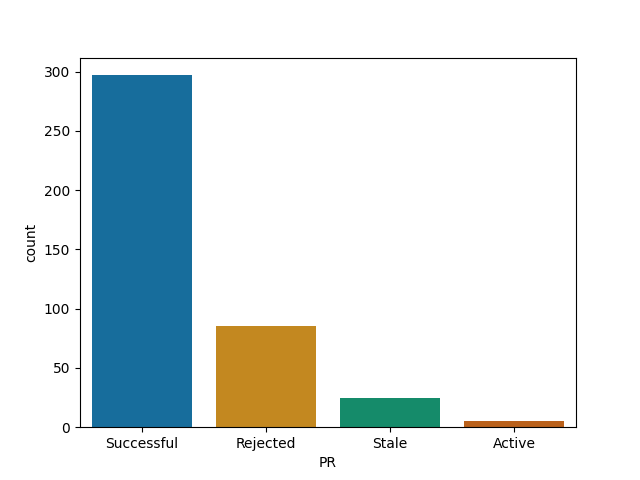
ggplot2
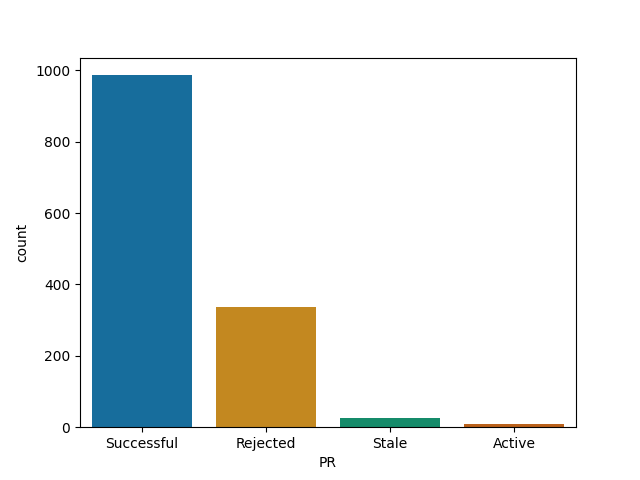
dplyr
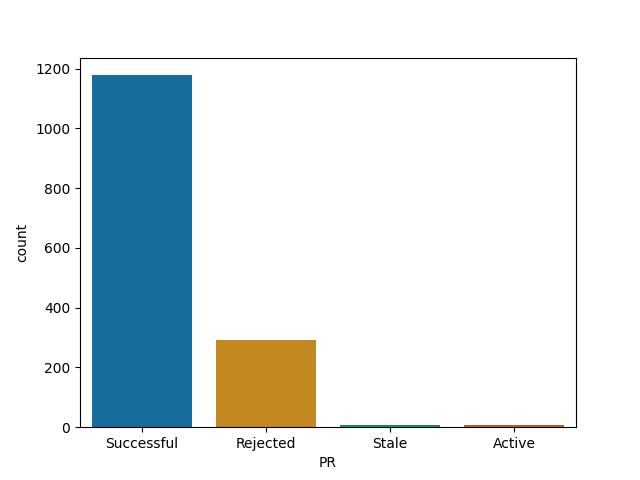
shiny
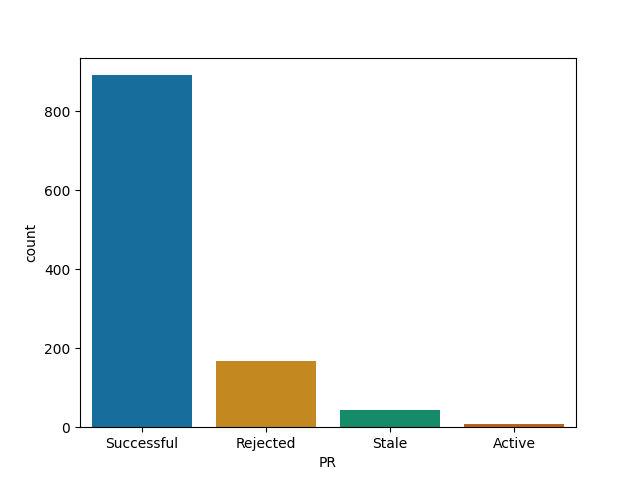
rmarkdown
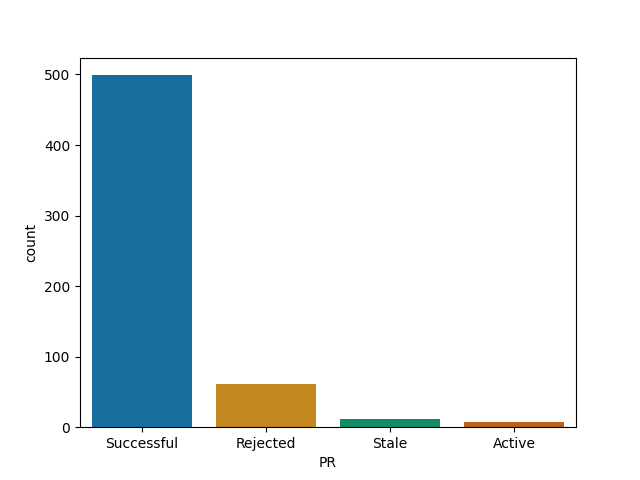
plotly
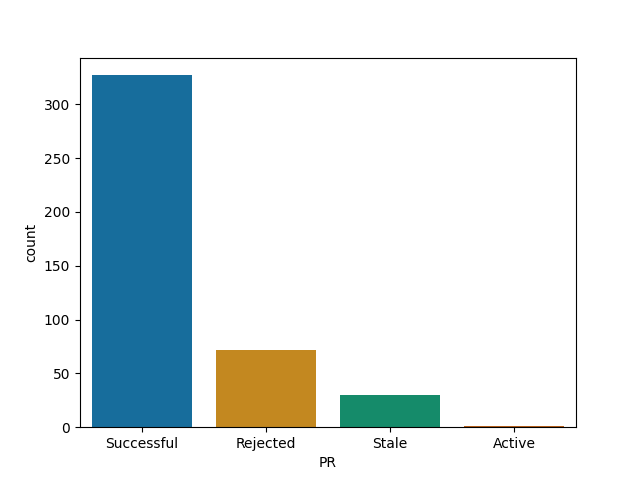
DiagrammeR
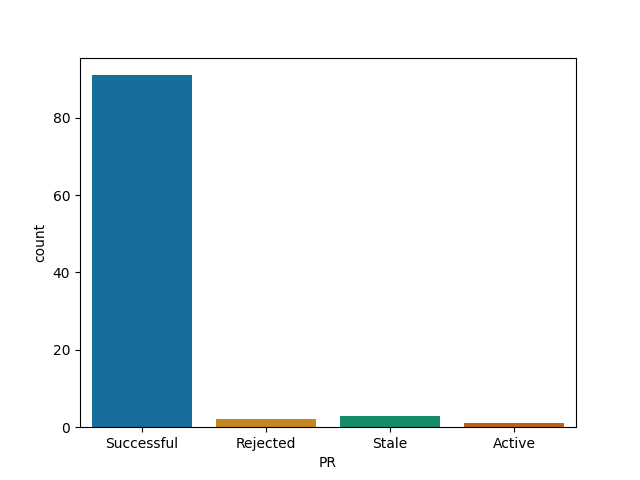
devtools
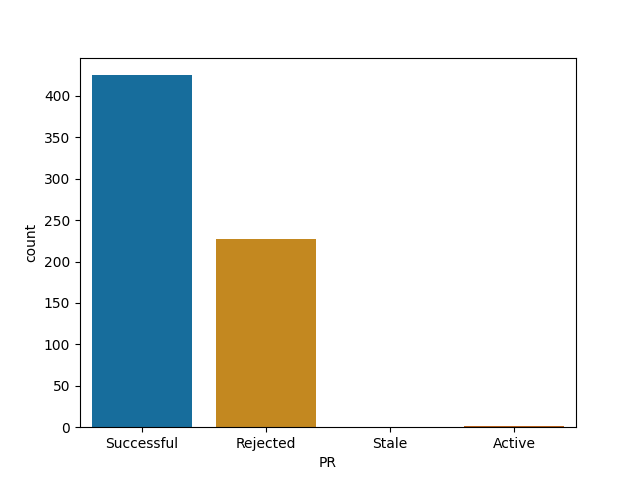
MLR
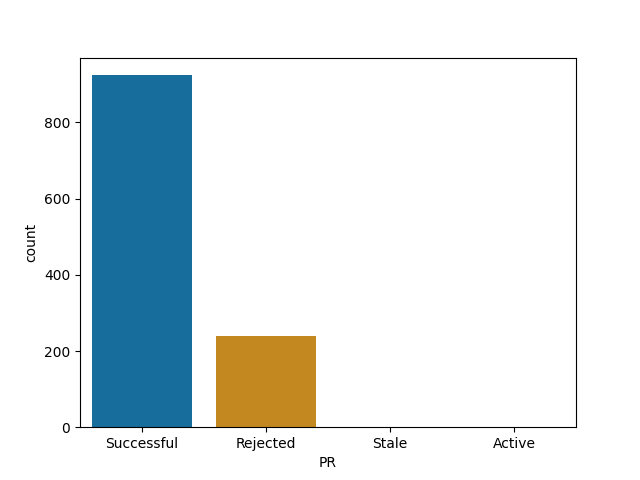
r4ds
Conclusions
Based on this limited analysis (it is in the end just a ratio of merged vs other PRs) it seems that big JavaScript projects are less good of an investment of your time when it comes to making a PR, although the analysis does not take spam into account yet, so take it with a grain of salt. Julia with its rapidly developing ecosystem is quite an attractive target for contributions however!
Would you like to get a PR stats plot like above for some other repo? Use my script.
Follow me on twitter for more content like this!