When to dump JSON?
Staff Engineer at Instruqt
Disclaimer: This is a fairly specific benchmark, it addresses only serialization performance of a single big Python object. That was the problem we were solving at the time at Plotwise. It might not be relevant to any other case, but you can probably adapt our benchmark code to test for a different scenario.
In this post I will answer the following questions At what point (or what size of an object) does it make sense to stop using Python’s json from standard library? Which of the mainstream library choices performs best latency-wise? You may instinctively know that JSON is not the most efficient format. It is human readable, which means it is pretty redundant as far as efficient encoding goes (think for instance of all the keys that need repeating, or the need for utf-8 encoding). Let’s say you are dealing with a single, big structured data object (Python class instance more specifically ..), is it worth using binary encoding? Or better dump it into Json? What about pickling? How much speed can you possibly gain at what cost to the code complexity?
Data Structure for Route Planning
The use-case we have at Plotwise is storing a snapshot of a route planning. Those plannings grow with the number of delivery events, vehicles and driver shifts. They also change dynamically as they are optimized over time. It is important for us to be able to quickly serialize (…dump) the planning and persist it, but also to be able to restore it from persistence. The planning is a nested multi-field JSON with mostly numeric fields and some low-cardinality string fields. A typical planning would be anywhere between 200 kb and 1.5 mb. At this size the benefits of switching to a more compact format should start to be apparent. But how big would it be exactly? Is it worth it? Speeding up the serialization of the planning will have real impact on our planning application. Not only do we create the planning snapshots often, we also would like to be able to restore an object from the snapshot on demand as quick as possible. For purpose of this benchmark I chose the following contenders:
- msgpack, no need to define schema, a drop-in replacement for json.dump and json.load. Widely used.
- protobuf, requires schema to be explicitly defined and compiled. Also widely used.
- pickle from python std-lib. Python specific binary format for serializing objects as-is. Less widely used despite its accessibility, probably because of concerns about performance, security and interoperability. Some of these concerns are outdated.
- json from python std-lib. Our baseline, as this is what we currently use.
How I Measured
You can run the benchmark yourself using this repo. In short, my test setup consists of a couple of pytest + pytest-benchmark tests which run dumps and loads equivalents from different serialization libs that we chose. pytest-benchmark runs each test multiple times to get more accurate stats. Important to this benchmark setup is the test object shape and size. A typical benchmark you may find on this topic is usually in the web context, where the use case for often revolves around the high number and velocity of messages sent over HTTP or other network protocol, not about dealing with single but huge objects dumped to the file-system or cache. The test object consisted of two arrays which size was parametrized in our benchmark. First array consisted simply of random floats, second of dicts each containing random int, random float and a random string of fixed size. This is to emulate rough shape of the planning snapshot, or at least its growing part.
I tested following object sizes (in number of fields): 4, 40, 400, 4k, 40k, 400k, out of which the biggest sample (400k) for all libs is discussed and visualized in this post and 4, 400 and 4k are used to test the threshold at which it pays off to stop using json. The rest of the results are in the github repo . With the biggest one being the most instructive to our own use-case and the smaller ones used mostly to find the threshold at which it pays off to stop using std-lib json. I ran the benchmarks with cPython 3.8.11 on my ThinkPad laptop with gen8 Intel 7 processor, 16gb of RAM, PopOS 21.04.
Results
First the results for the big object serializaton for each of the mainstream libs.
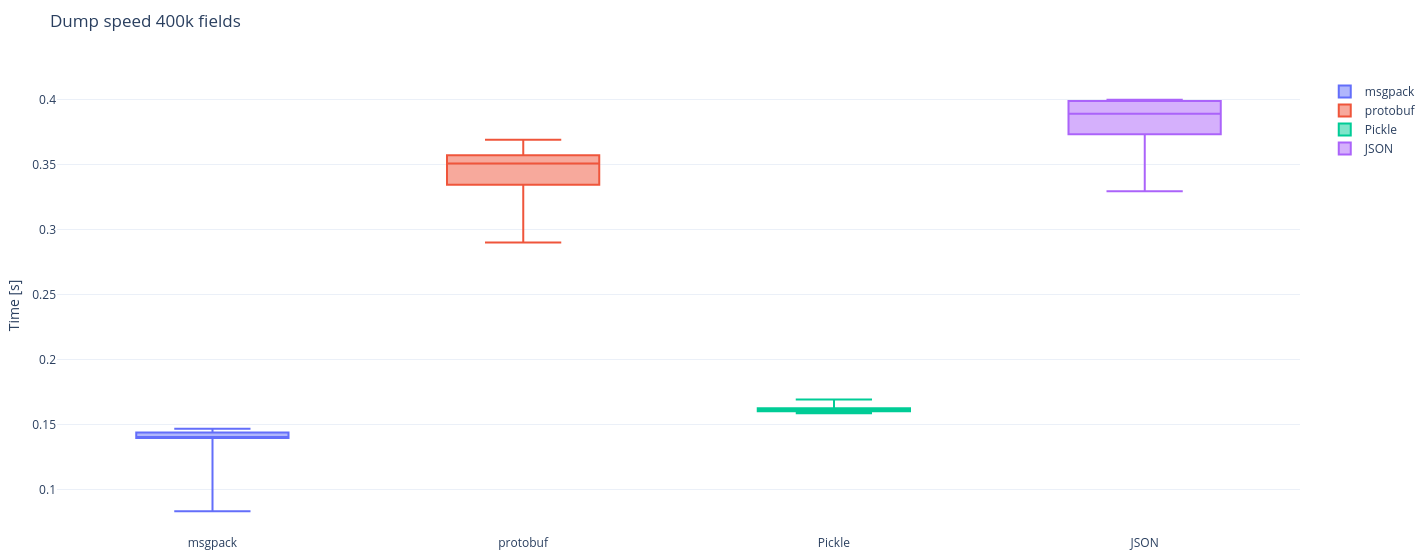
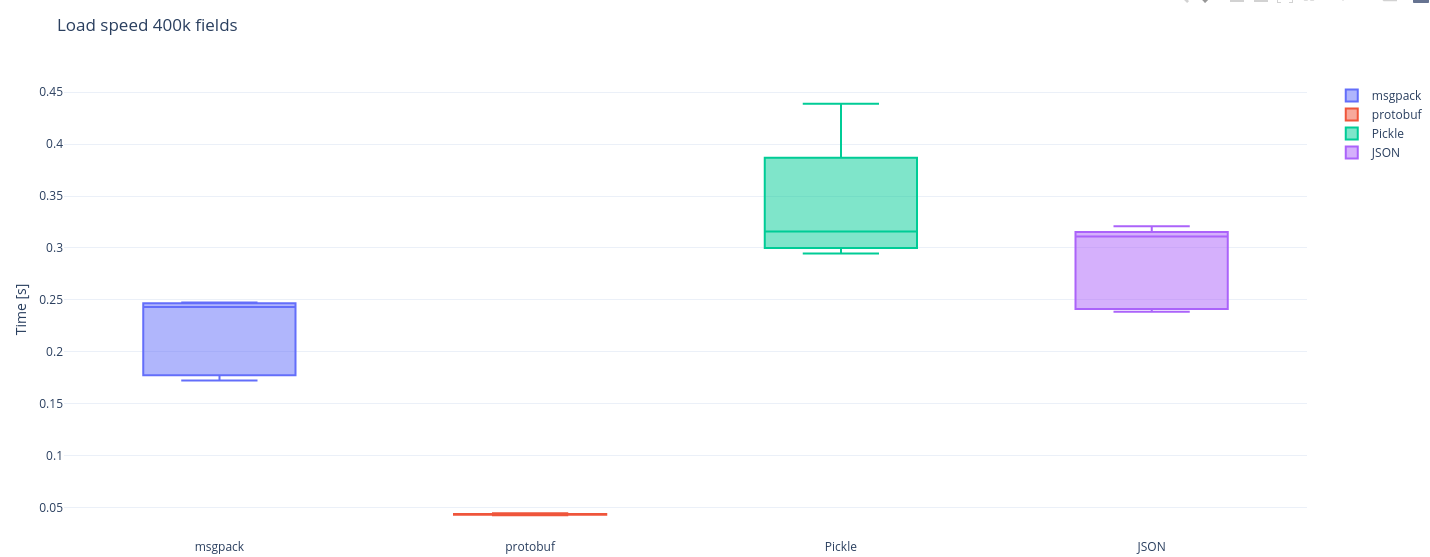
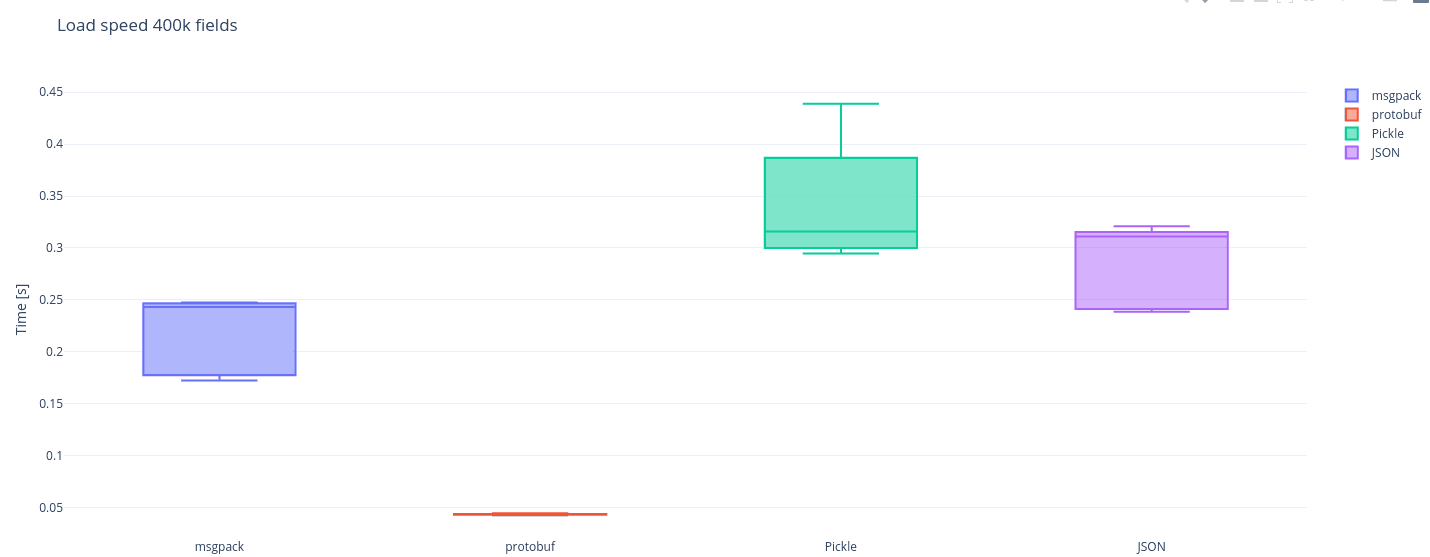
msgpack and pickle are the fastest in dumping a single 400k fields object
Protobuf really stands out with its load performance The data is visualized as box-plots, pay attention to the middle horizontal line in each box, this is the median and also the most important metric for each benchmark. The differences between medians for dumps and loads of the libs in our benchmark are substantial and json is pretty far from the winner. There is still quite some nuance on which is ultimately a better choice: protobuf with its outstanding load speed or msgpack with its winning dump? In our case it is msgpack, because we need both dump and load to be fast as we perform these operations equal amount of times. Now to the results that will help us establish for what size of an object does it start paying off to switch to msgpack?
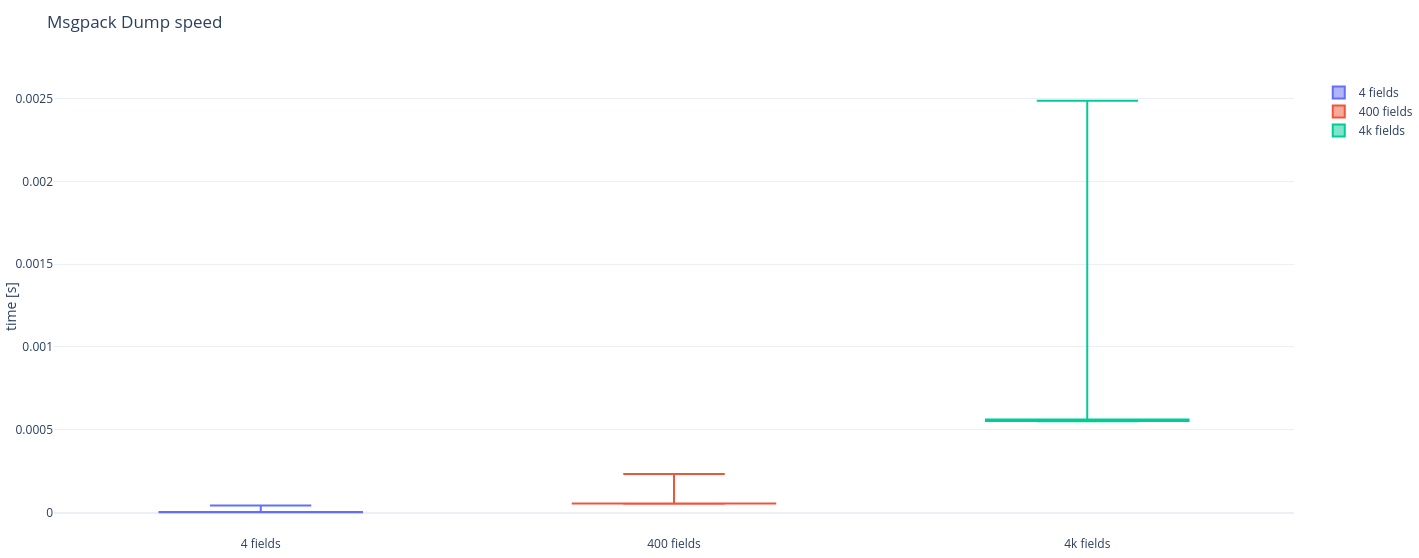
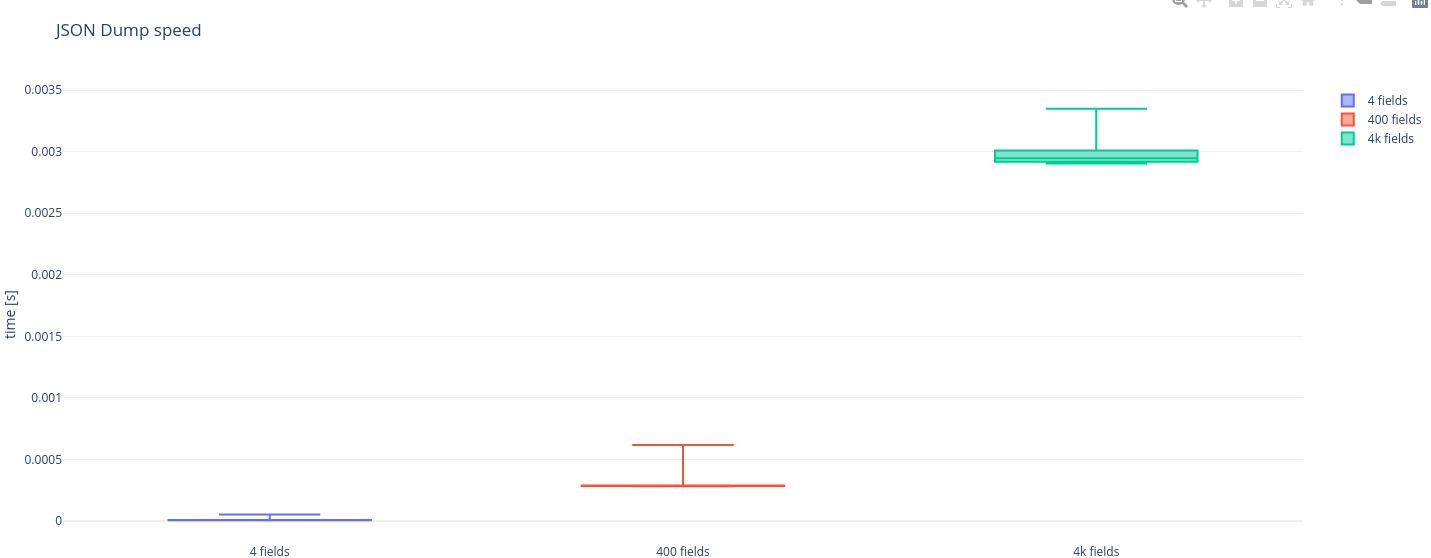
It seems that even for an object with just 400 fields the difference in latency is already visible and significant. In short: msgpack is a pretty solid choice whenever performance is a consideration, the size of an object to serialize at which it starts to pay of is actually quite low, for our use-case it seems a fairly simple choice to go with msgpack.
If you would like to dig deeper into the results, you can find the full data in a csv in my github repo .
Conclusions
- When considering dump speed alone, json is truly the slowest of the mainstream options. for the load speed, json is doing a bit better, but it still falls behind msgpack and protobuf. It does pay off to stop using json from python std-lib for bigger objects. You could achieve even 2.7x speedup in dump speed with msgpack or a whooping ~7.7x speedup for loading with protobuf.
- The easiest option for speed up (given you currently use json, as we do) is msgpack. It is a drop-in replacement which won’t introduce too much complexity to your code-base but will decrease both latency and size of the dump.
- If your pattern of use is: dump once/rarely and load many times, protobuf is your friend, just look how much faster it is in loading than any other lib in the benchmark.
- Pickle might still be a good choice, its performance has improved with protocol 4 and 5. It allows for skipping init() and simplify your serialization code. Typical caveats still apply though, you should unpickle only the data you trust and it is limited in its use for inter-process-communication.
We are hiring! Check our career site !